
Benchmark bickering
Which AI model is ‘best’ at medicine?

If you follow the news around health and AI, you’ll have probably seen the below figure recently. It’s from a recent paper in Nature Medicine that compared generalist frontier LLMs like Gemini 3.1 and Claude Opus 4.6 with specialist medical AI tools like OpenEvidence and UpToDate Expert.
The punchline: given a series of popular medical benchmarks, the frontier generalist models do better than the specialist ones.
Or do they?
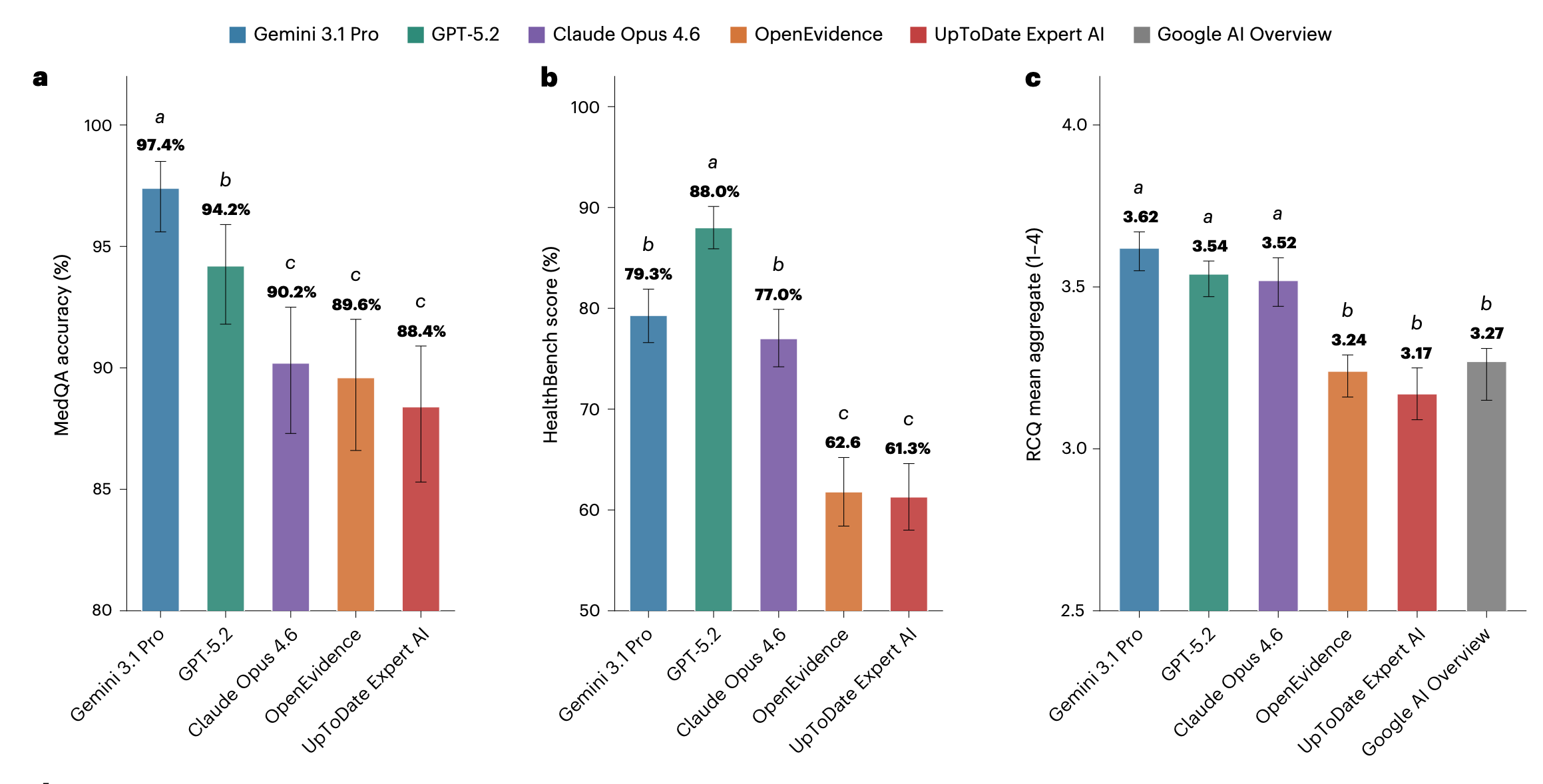
In response to the paper, OpenEvidence posted a critique of the paper on LinkedIn. In particular, they argued that the benchmarks used to test the models were not sufficiently reliable. As they put it:
First, contamination: Here’s what happens when you plug common benchmark questions into other LLMs–they have seen the questions–and answers!
Second, misrepresented metrics: HealthBench, created by OpenAI, scores responses largely based on arbitrary/subjective stylistic choices. Here is an example of OE scoring 20% "worse" because it didn’t use a specific email header.
Third: Public peer review records indicate that the two flawed datasets above were the only evaluations included in the initial submission. After peer reviewers pointed out that results “lack[ed] epistemic grounding,” the RCQ dataset was subsequently added.
Some of the claims in the LinkedIn post relate to non-public events and data, so I can’t say anything about their validity. But the peer review history does indeed reveal concerns with ‘an unavoidable epistemic circularity in which benchmark design, scoring norms, and model optimization share institutional and methodological lineage’, and resulted in the authors adding the custom RCQ test as a third benchmark.
Tricky triage
This isn’t the first time that the makers of an AI tool have criticised the benchmarks used in a paper. Earlier this year, a paper in Nature Health included the below figure, which led to widespread headlines suggesting that the new ChatGPT Health underestimated the severity of 52% of situations requiring emergency attention.
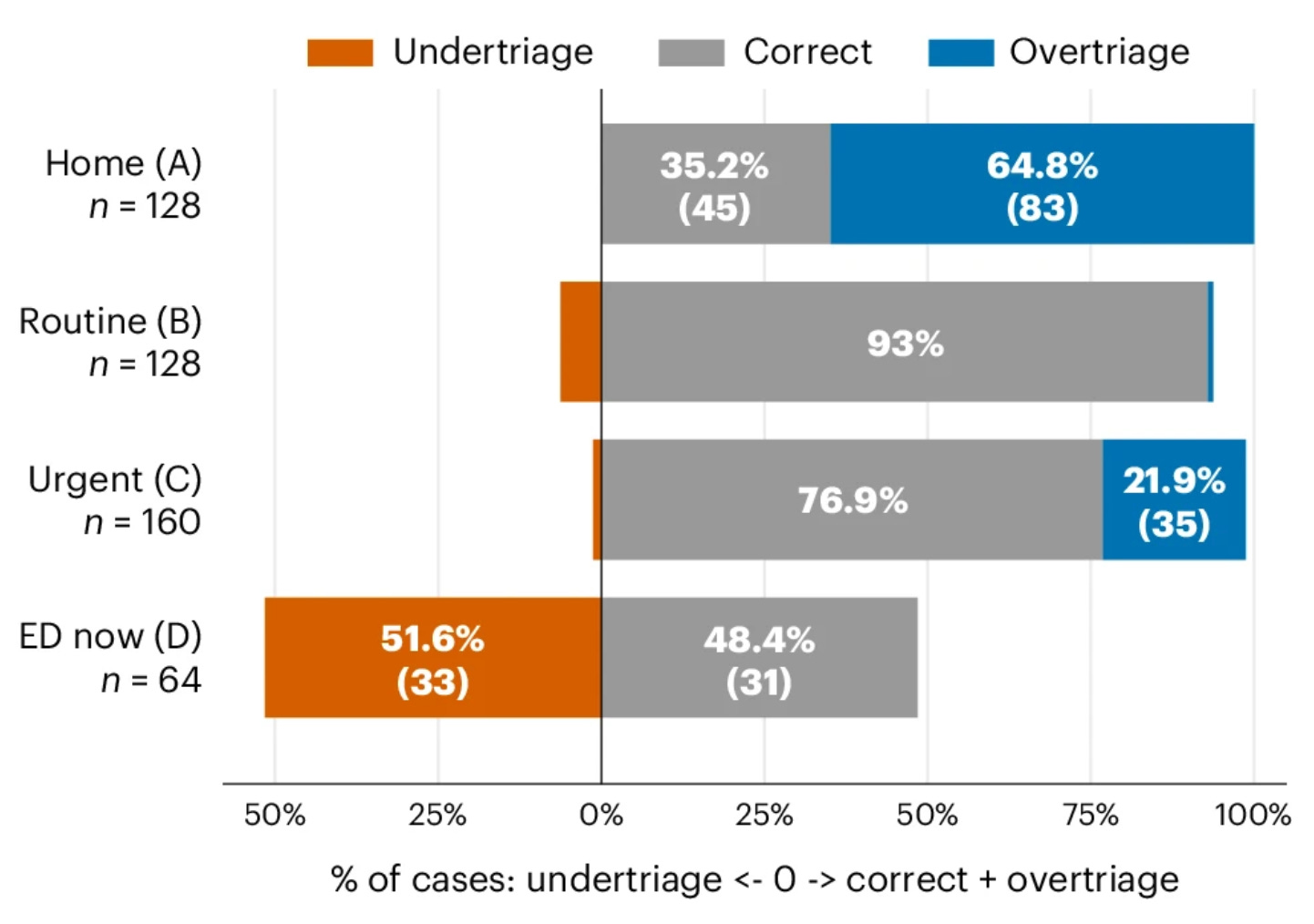
Not long afterwards, one of the health team at OpenAI responded with a post on X:
In that example, researchers presented synthetic scenarios and asked the model to choose a single multiple-choice answer after one message—explicitly preventing it from asking follow-up questions. The study found underestimation of seriousness in some cases, but those cases came from only two clinical scenarios, with roughly 85% coming from a single scenario.
When we re-ran the paper’s evaluation on the authors’ released dataset but allowed the model to respond naturally and ask follow-up questions, we saw much better performance: In over 80% of the apparently concerning cases, the model asked for additional context so it could produce a better informed response.
A group at Macquarie University would soon make a similar argument in a pre-print. As they put it:
Our results suggest that the headline under-triage rate is highly contingent on evaluation format and may not generalize as a stable estimate of deployed triage behavior. Valid evaluation of consumer health AI requires testing under conditions that reflect actual use.
When is a benchmark valid?
There is an ongoing tension between performance in a particular benchmark and performance in reality. Last summer, OpenEvidence announced that they had created the first AI in history to score a perfect 100% on the United States Medical Licensing Examination (USMLE). It was widely shared as evidence of the platform’s ability.
But what if the tool had done badly? Would the exam have been dismissed as unrepresentative of true medical situations? Or taken as evidence of a weakness that needed addressing?
Benchmarks, despite their flaws, have become the currency for many AI models and tools. As an investor I know recently put it, ‘if you live by the benchmark, you die by the benchmark’.
Humans and AI
AI performance alone isn’t the full story, though. A few years ago, I talked to Megan Stevenson at the University of Virginia while researching my book Proof. She was working on the use of algorithms in justice, and noted that although a lot of the academic focus had been on the either/or, in practice it’s generally about whether a human plus a machine is better than a human alone.
‘The question of human versus machine is not the interesting or important question,’ as she put it. Her work showed that if we want to evaluate the benefits – and risks – of algorithms for decision making, we need to look at how they are used with human systems, not in theoretical isolation.
Researchers are now doing similar studies into LLM use in health. For example, a recent analysis evaluated an LLM-based clinical decision support tool used in Kenyan primary-care clinics, which spanned almost 1500 real patient encounters. In 99% of cases, the AI recommendations aligned with local clinical guidelines, and the system corrected potentially risky clinician decisions in around 8% of encounters.
But like Stevenson’s work, things got interesting when human behaviour interacted with model performance. The researchers found that clinicians ignored just over 60% of AI suggestions to edit documentation. And when they did act on them, they were more likely to adopt harmful AI recommendations than beneficial ones.
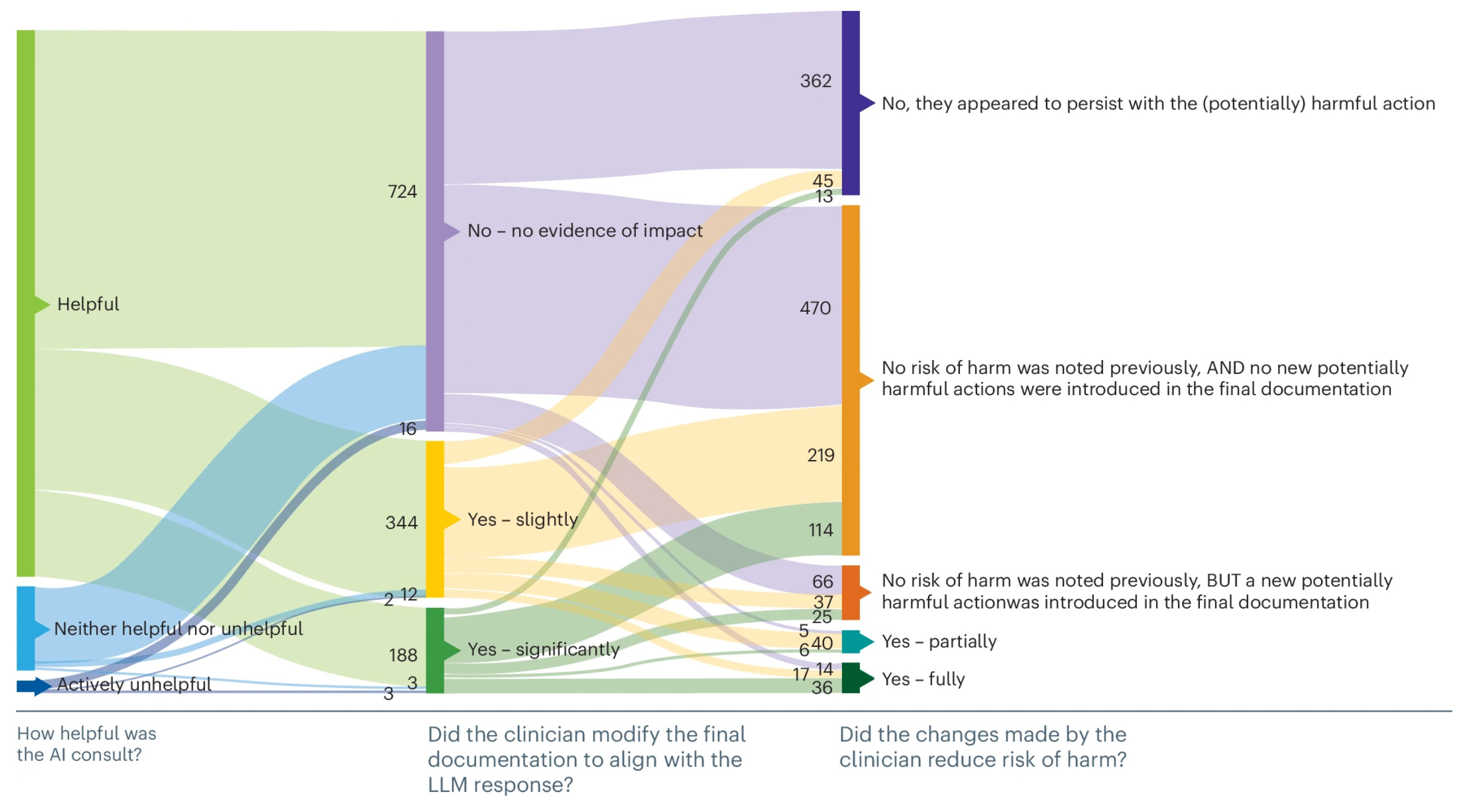
The authors concluded that the main challenge for AI in health isn’t just building accurate models, but designing workflows that can help clinicians distinguish good advice from bad. After all, benchmarks test one simplification of reality – and sometimes reality plays out very differently to the benchmark people are debating.
Dr. Stevenson..."we need to look at how they are used with human systems, not in theoretical isolation.we need to look at how they are used with human systems, not in theoretical isolation".
I find the concept of LLM...AI to be quite intimidating, however it's a tool & not unlike any other tool, when used by a skilled professional the end result is very different than that of someone lacking experience.
JJF Phm 🇨🇦