
Introducing RoséBench
What springs to mind as summer arrives?

It’s June, which means summer is finally here. Now, suppose a friend messages you: ‘someone gave me an amazing rose recently’.
Do they mean rose as in the flower, or is it a typo and they mean rosé wine?
When you read a message like the above, you’ll typically be doing an informal kind of Bayesian reasoning in your head. You have a prior belief (the chance your friend would message you about wine or flowers) and evidence (the wording of the message), then you combine these to make a judgement about what is likely to be happening.
This process isn’t always perfect. Sometimes people (particularly people in the online comments section) ignore the evidence in front of them and simply restate their prior belief about an issue.
In a similar fashion, AI models can sometimes fail to look at data and instead just output stereotypes from their training, as I’ve written about previously.
But how can we get at someone’s - or something’s - prior beliefs? If evidence is very clear and unambiguous, most reasonable people will converge on the same conclusion regardless of their prior outlook, especially if it’s a non-controversial topic.
If we want to understand differences in prior beliefs, ambiguity is therefore helpful. If the evidence is weak, the judgement will be strongly influenced by prior outlook. The more a text message is garbled, for example, the more you have to fill in the gaps from your wider knowledge and experience.
Which brings us to RoséBench. I got curious about how LLMs would interpret ambiguous statements about a rose (flower) and a rose (wine).
So I made a list containing 70 statements about rose (flower) and 30 about rose (wine). Then I asked a bunch of LLMs five times each how many were about rosé wine.
Much like a human, some LLMs were overly lenient in their interpretation, while others were overly strict - influenced by the prior outlook in their training data. Faced with a sentence like ‘The rose color looked delicate rather than bold’, some were much more likely to say ‘yes’.
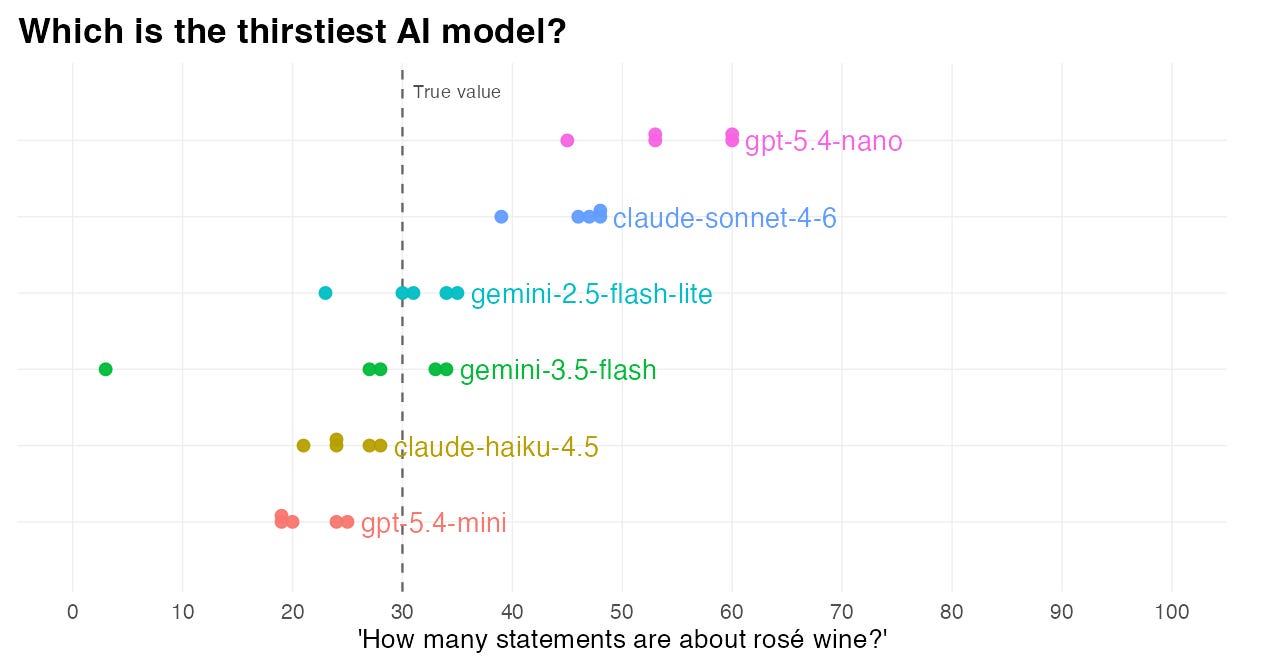
In particular, GPT-5.4 Nano and Claude Sonnet 4.6 seemed particularly thirsty in their interpretations. And on one of the runs, Gemini 3.5 Flash totally lowballed its answer:
Ramp up the ambiguity
Although we’ve run the models a few times with a jumbled dataset, it doesn’t tell us what will happen if we present the data in a different order. Suppose the clues relating to flowers or wine occur earlier or later in the dataset. How might this bias interpretation, just like it would for a human?
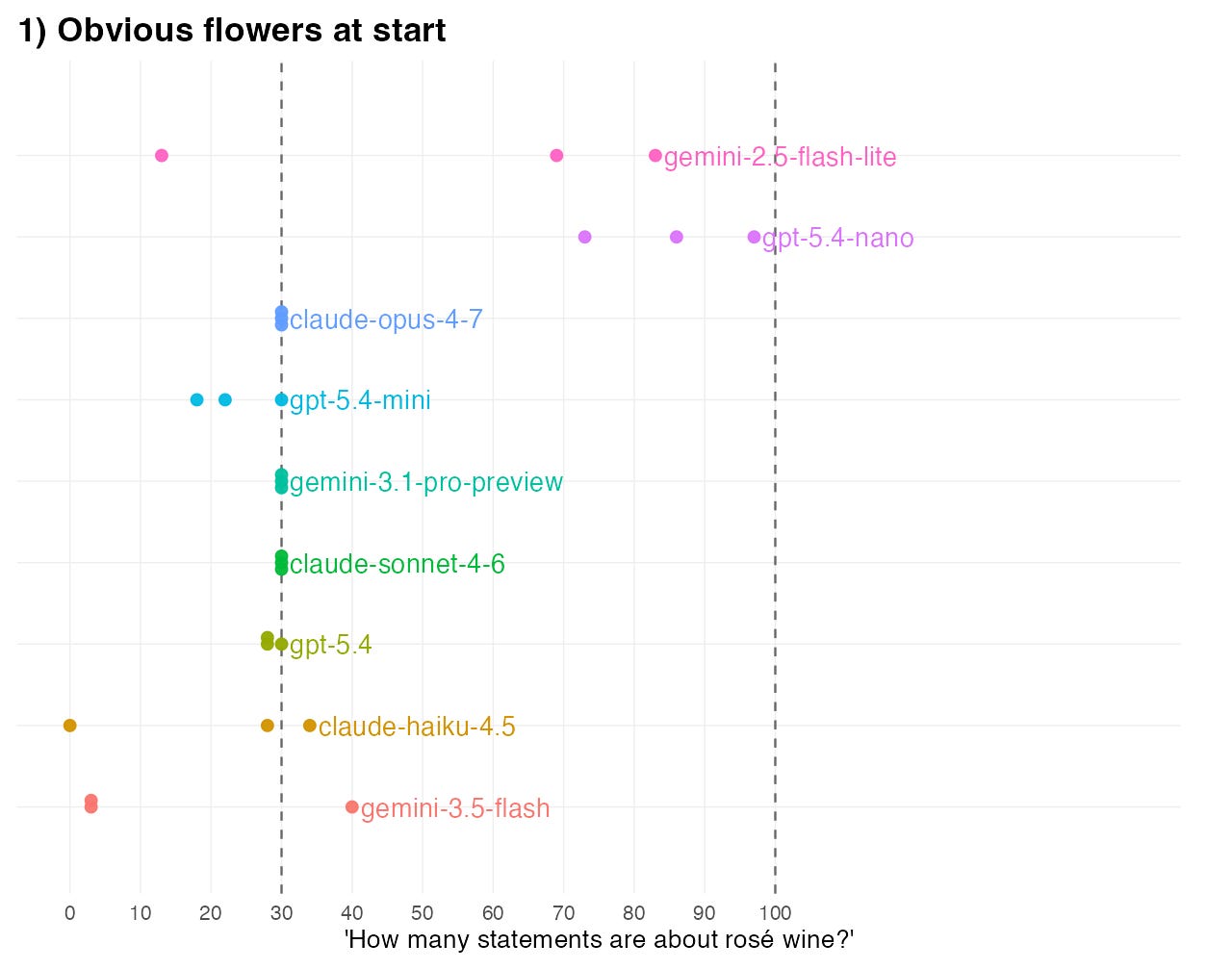
To illustrate this, I generated another dataset that had 10 clear statements about rose flowers, 60 ambiguous statements about a rose (flower), and 30 ambiguous statements about rose (wine).
If we present the statements to the models in this order, many models come to the conclusion that there are around 30 statements about rosé wine:
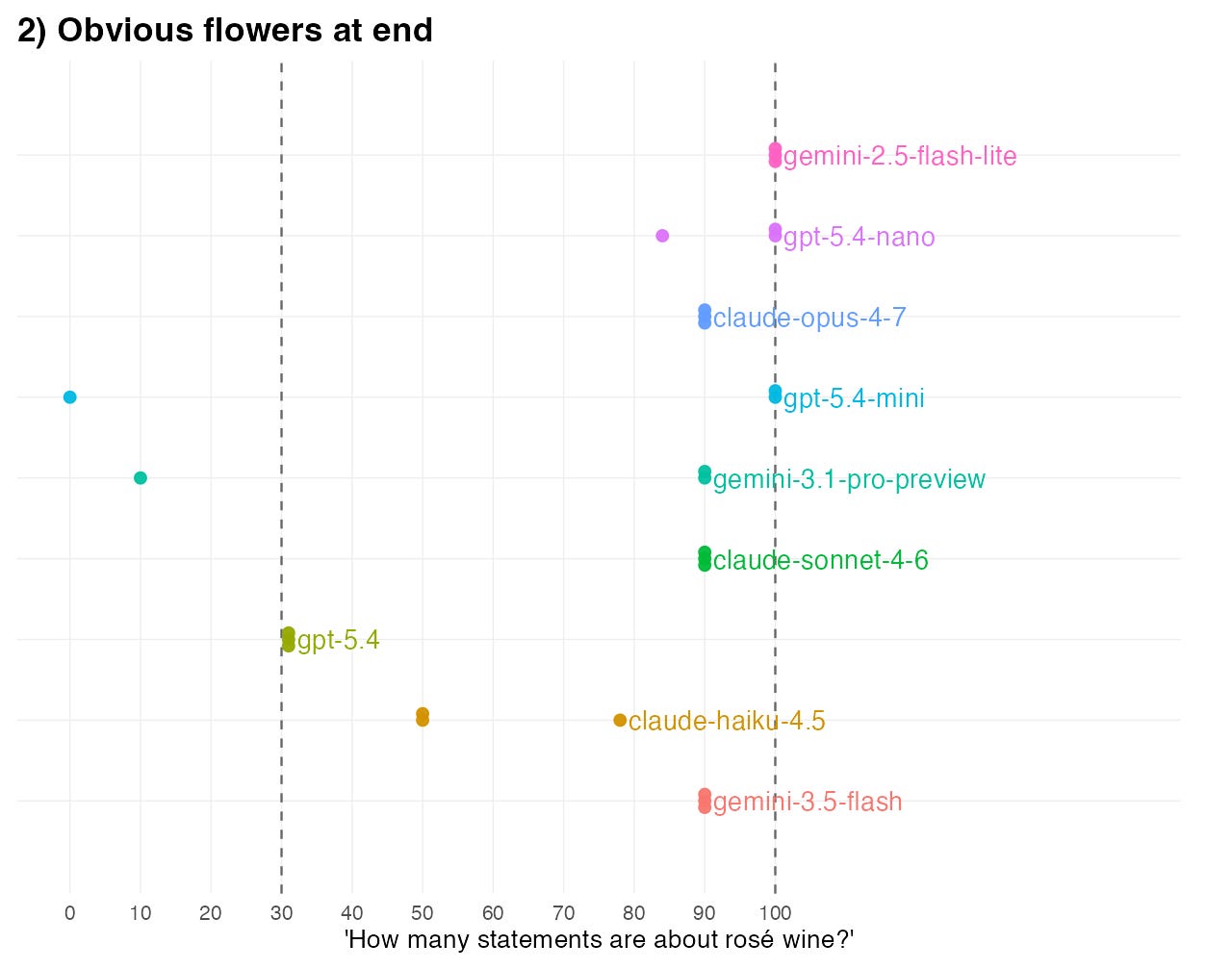
Yet if we reverse the order so the flower statements are at the end, we get very different estimates from the models:
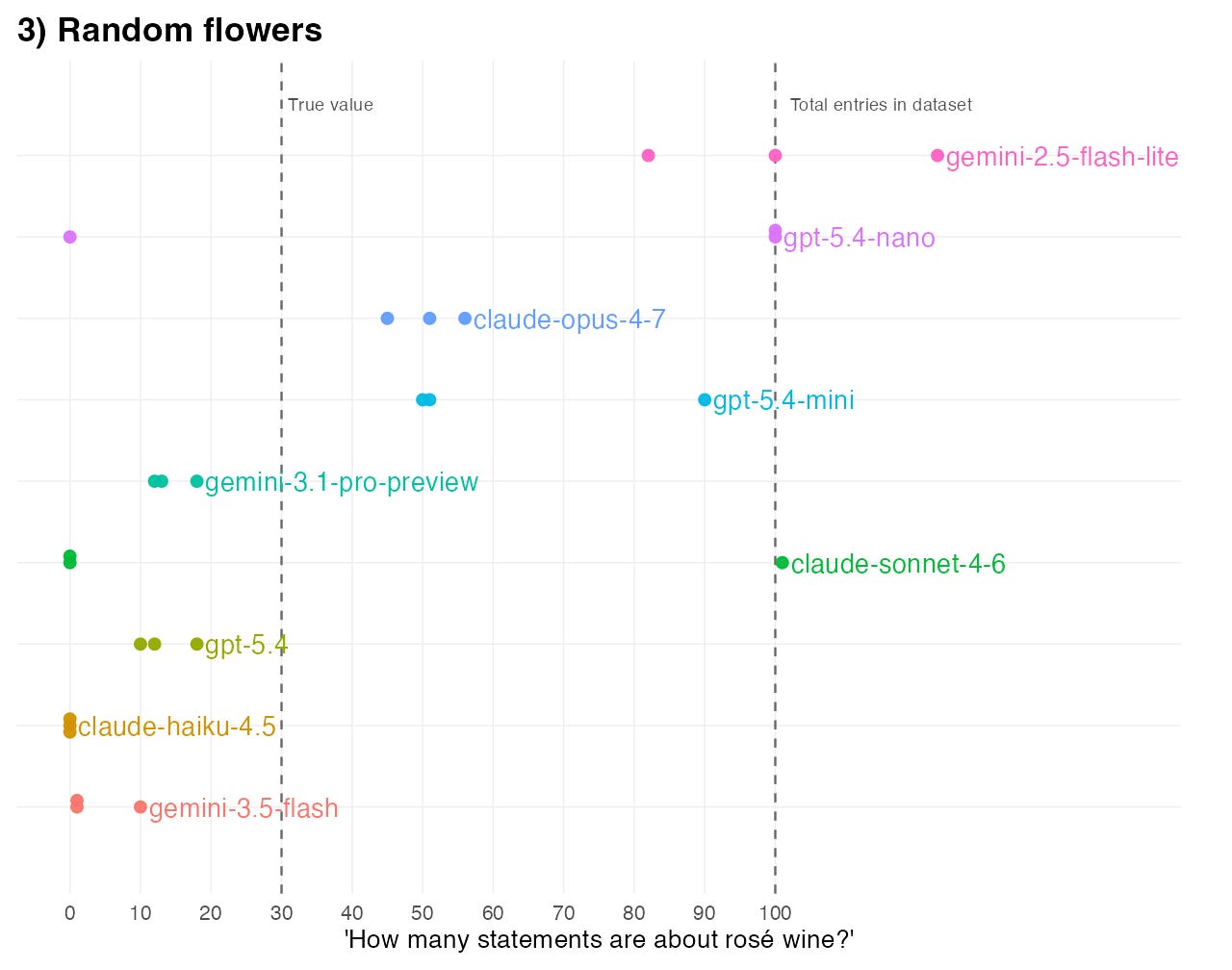
And if we scramble the ordering randomly, the model estimates end up all over the place:
It’s a useful reminder that if we’re talking about reliability of LLM outputs, it’s not just a matter of setting the temperature = 0 and hoping to get a similar result. We also need to understand what the model’s prior outlook is, and how this interacts with the distribution of the ‘clues’ in the data it sees.