
Will AI chatbots put an end to open source software?
Freely available software relies on credit and attention. AI is destroying that.

Last year, I noticed that LLMs had got a lot better at questions about epidemiological software tools. Previously, if you’d asked it for ways to estimate a reproduction number, you’d have got a method from a decade ago, without a clear explanation of its limitations.
Now it can give you a useful breakdown of different methods, and how they compare. My colleague James Azam, who’s done a lot of work recently on the EpiNow2 package for reproduction number estimation, has pointed out one big thing that’s changed in the past year or two is the documentation for these packages. As part of the Epiverse initiative, a large collaborative effort in recent years has added explanations, case studies, walkthroughs, and tutorials.
Epiverse Learn is now probably the largest set of freely available training materials for outbreak analytics and modelling in R out there (and is designed to complement the excellent epiRhandbook for applied epidemiology and data science in R).
Having code explanations and examples to hand can make AI-assisted work much more powerful. Last year, I ran some drop-in sessions with our outbreak analytics and applied modelling short course cohort. As part of one session, we used GPT to adapt an existing model in real-time, in response to a participant question about how to incorporate waning immunity:
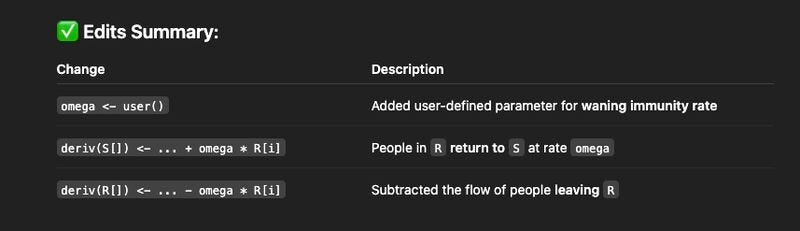
AI is generally pretty bad at developing disease models from scratch. Lots of exploratory posts have used it to generate a single population SIR model, but this is basically the 'hello world' of infectious disease dynamics, and practically nobody uses this as-is for actual research or policy. But what AI can be good at is suggesting how to adapt existing well-documented models in well-defined ways, especially if asked to explain logic along the way.
This is why having libraries of case studies (e.g. those in Epiverse and emerging in other ecosystem packages) is so valuable. It solves the standing start problem, and turns a dodgy from-scratch AI model into a useful training exercise. But it requires a lot of domain knowledge to create these resources – the shoulders on which students can now stand and peer further with the help of AI.
And those shoulders are increasingly becoming invisible.
Open-source, closing down
Last week, the CEO of Tailwind Labs, which makes a popular open-source CSS framework, announced they were having to lay off three quarters of their engineers. He pointed to the ‘brutal impact AI has had on our business’, which relies on users visiting the website and converting to their commercial plans. If you can get the code you need via an external AI chatbot, there is no incentive to visit, and no opportunity to discover these options.
Tailwind isn’t the only example of open-source code struggling. Yan Holtz maintains several popular galleries with data visualisation examples and code. But earlier this week, he announced on LinkedIn this would no longer be openly available:

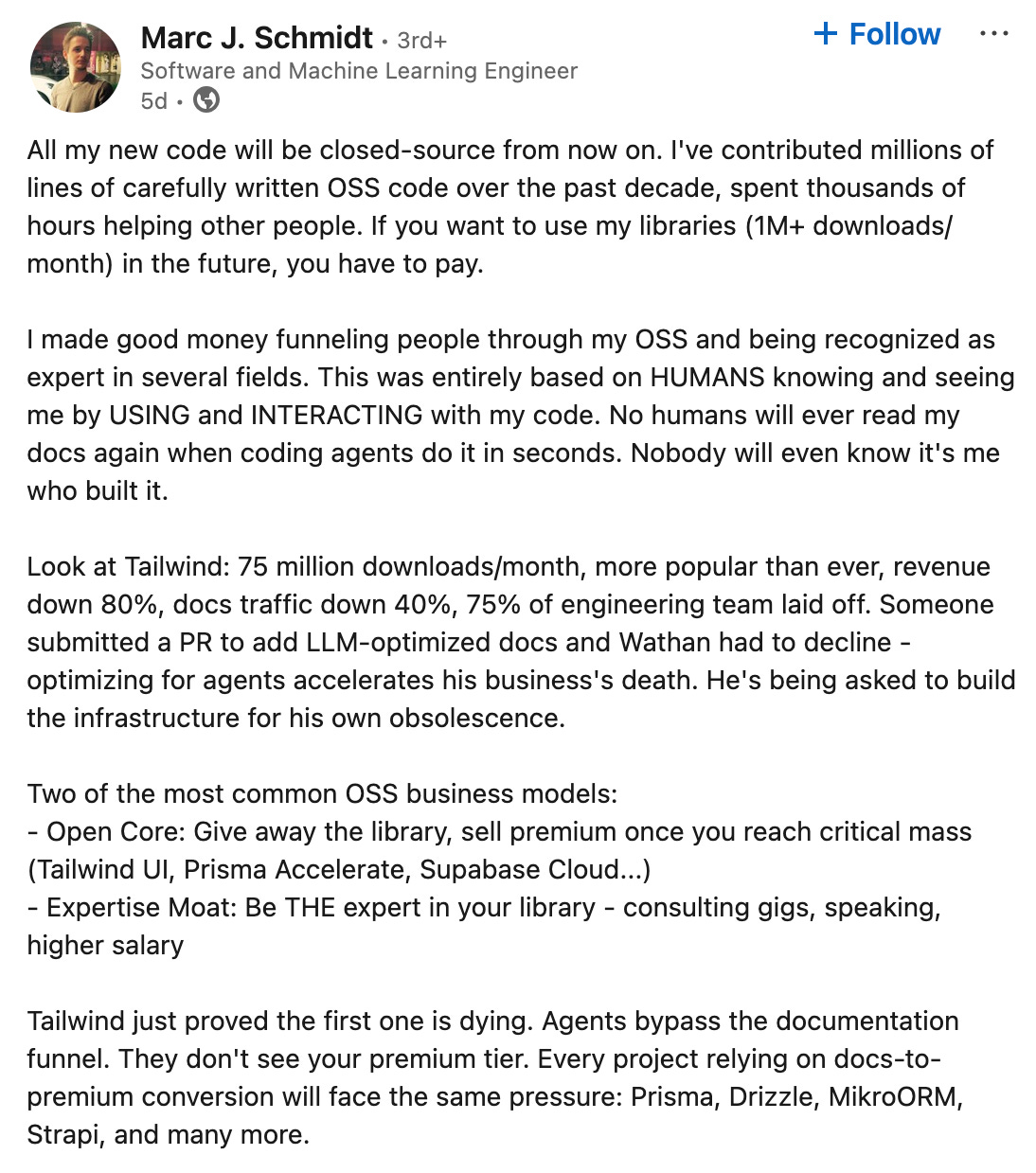
A few days before, Marc Schmidt had made a similar announcement, motivated by the events with Tailwind:
Free but not free
Open-source tools and software might be available for free to users, but that doesn’t mean that they are free to make, or that creators don’t have to think about where the time and money to build and support them will come from. Take Our World in Data, a hugely valuable public resource, but also one that has often had to fight for survival. As Max Roser has noted:
A large part of my time and energy is dedicated to finding the funding for this research and to build these freely accessible publications. It is, unfortunately, very difficult to finance the work of Our World in Data. This is definitely the worst part of my job. If this was not such a big part of my work, we would be able to do much more.
If people can’t see who is doing the underlying work, it becomes difficult to engage or support them. In his full post on open-source software, Marc Schmidt sums it up well:
The core insight: OSS monetization was always about attention. Human eyeballs on your docs, brand, expertise. That attention has literally moved into attention layers. Your docs trained the models that now make visiting you unnecessary. Human attention paid. Artificial attention doesn’t.
Some might argue that we no longer need human-created resources and codebases, because AI can now generate new code by reading AI-generated code. But this makes the heroic assumption of a closed, self-sustaining loop that doesn’t currently exist in reality. Today’s models work most effectively when they can source inspiration from human-designed architectures, examples, and explanations. Once that pipeline dries up, AI will be stuck rehashing the same old content.
This is already starting to happen. As attention moves from people and projects to AI chatbots, the incentives to publish high-quality, openly documented work will soon fade. And once valuable open source knowledge will increasingly live behind closed doors.
Cover image: Muhammad Zaqy Al Fattah
“And once valuable open source knowledge will increasingly live behind closed doors.”
Legally, books are behind closed doors. Buying the book doesn’t permit you to do to its contents what AI companies have done. But the AI companies have done it and got away with it. What will happen with Tailwind’s products once you have to pay?
Adam, thank you! these are all valuable resources that I did not even know before your introduction. It's quite frustrating.