
Can language models tell us what populations are thinking and doing?
Digital twins and digital spin

Over the years, I’ve worked on many studies of human behaviour, from social networks in schools to large-scale behavioural and mobility patterns in the UK and millions of interactions during events in Singapore. Each required careful planning and design, from logistics and ethics to data collection and analysis.
From education to economics to epidemics, it’s important to understand what populations are doing and thinking, but this takes time, money and effort. Perhaps things are changing, though. In the era of trillion-parameter AI models, trained on much of the internet, how much do we need to collect real data to understand what people are likely to say and do?
Synthetic surveys
Out of curiosity, I ran a small test: could a large language model (LLM) like GPT-4.1 predict the results of a real survey? This wasn’t a formal study, more a quick nap-time experiment while my baby slept, but it was an opportunity to get a feel for the problem.
One obvious issue with trying to create an AI ‘synthetic population’ is that LLMs have already seen huge amounts of online text, including historical surveys and commentary. So if you pick old questions, the model might just ‘remember’ the right answer from its training data. It’s what I’d call history leakage.
To avoid this, I picked a recent survey from YouGov, which wouldn’t have been around when a model like GPT-4 was trained (and unlike ChatGPT, the API model wouldn’t be able to search the internet). This was a recent survey on their website:
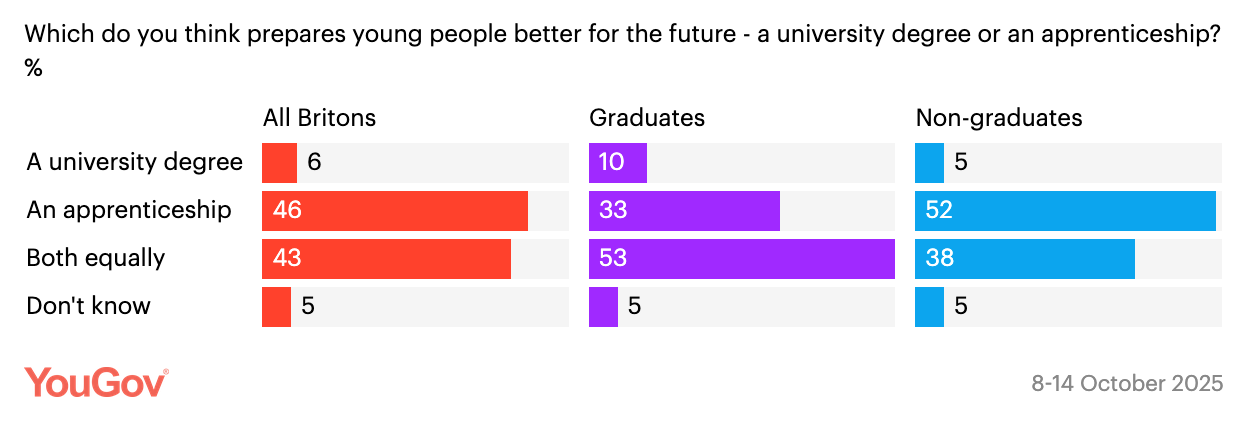
I then asked GPT-4.1 to generate 500 responses, with the following instructions:
‘You live in the UK in 2025. You are completing a YouGov survey and have been asked the following question: Which do you think prepares young people better for the future - a university degree or an apprenticeship? Only output the exact text of the option that matches your belief.’
I set the temperature to 1 (so responses were sampled directly from the model’s probability distribution) and scrambled the order of options each time to avoid position bias1.
The result was underwhelming: 100% of the AI respondents answered ‘both equally’.
Adding some ‘demographics’
Even though I’d scrambled the options in each run (to avoid bias toward certain positions in a list), GPT seemed to have a strong preference towards the fence-sitting option. But what if I included a bit more demography?
I therefore added a crude age to each AI respondent: ‘You are [X] years old’, where X was a random number between 18 and 80 that I’d generated. That might at least nudge the model toward some more variation.
The results were still far from perfect, but they started to look vaguely plausible (and probably better than I would have guessed off the top of my head):
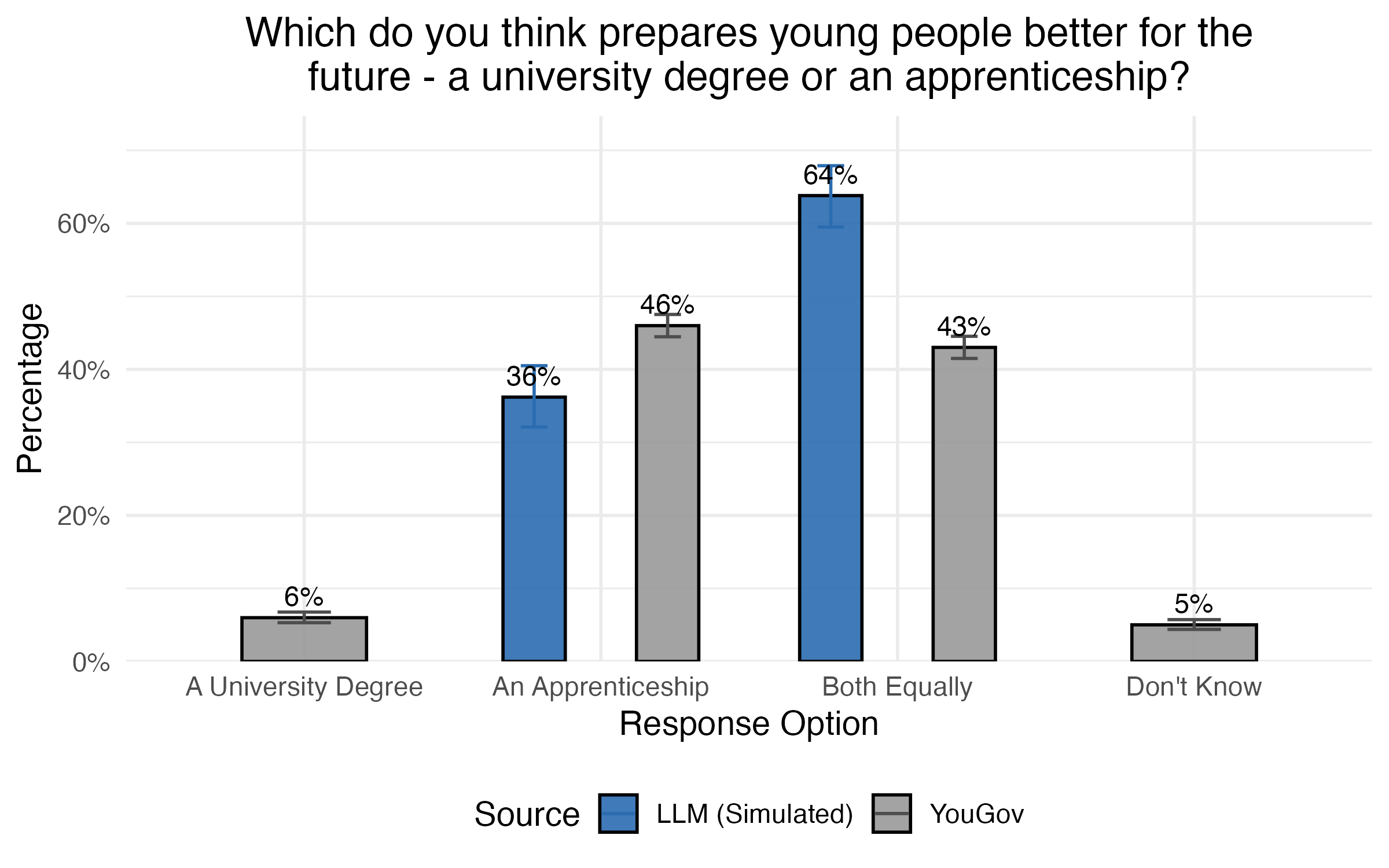
Next, I asked the model about political views. This time the result was even starker. Or rather, Starmer – my AI respondents were unanimous in where their vote would go.
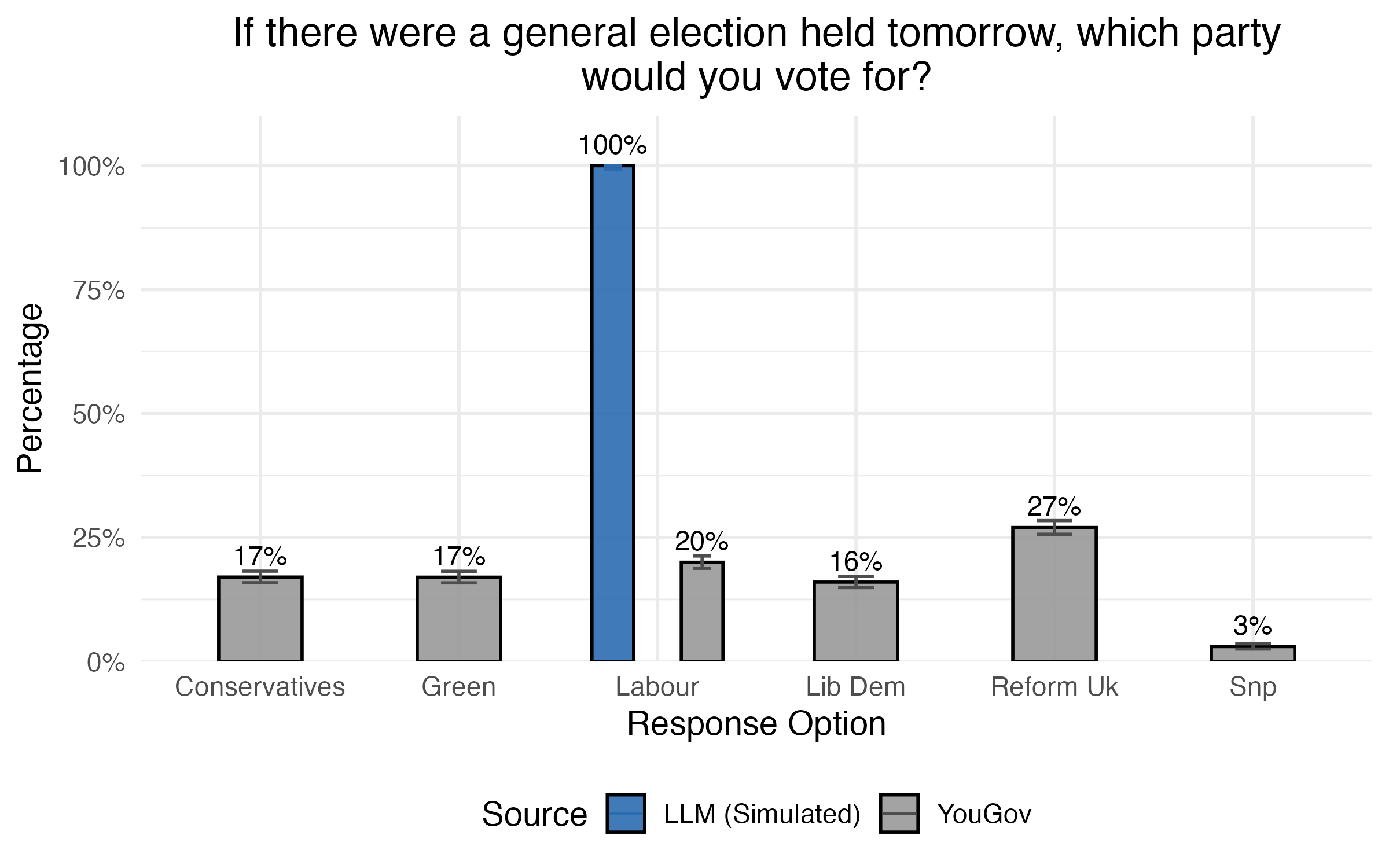
Things were a bit closer to the survey results when I gave each avatar ‘their’ 2024 voting choice as input, albeit with an overestimation of Labour support (even relative to their 2024 vote share):
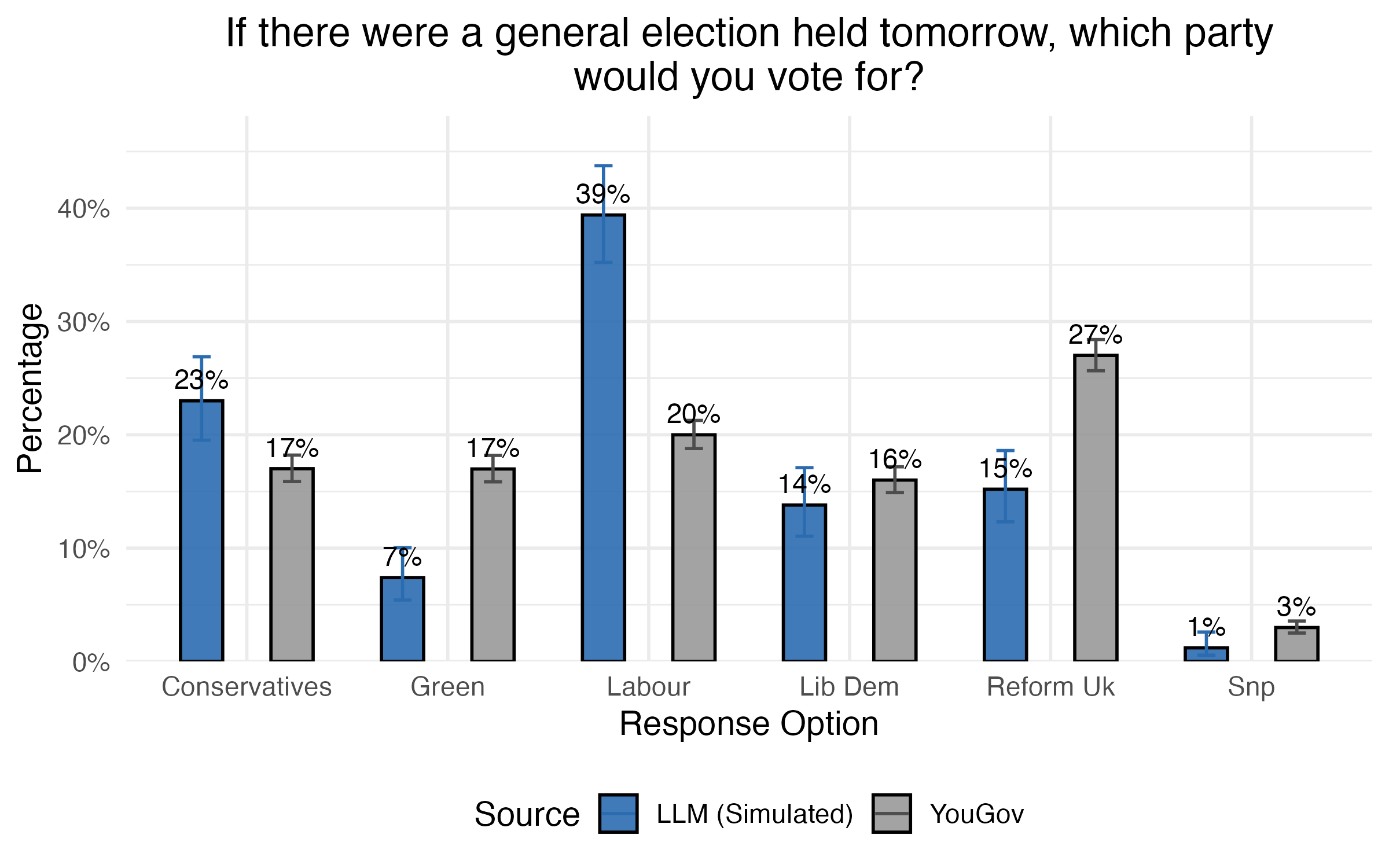
The key problem here is independence: generating 500 LLM completions doesn’t produce 500 separate synthetic people. It’s just one model sampled 500 times. Adding a random variable like age or previous vote gives us some rough conditioning on individual characteristics, but it doesn’t create proper demographic structure unless the LLM actually uses that information in a realistic, consistent way.
Pretend populations and real biases
This isn’t just an anecdotal finding based on my trial-and-error attempts. Several studies have found that large language models can give convincing looking answers to survey-style questions, but also that responses can diverge from human data in systematic ways.
Election studies. One 2024 study used the American National Election Study as a benchmark. While overall percentages roughly matched human results, the relationships between respondent characteristics and answers were often wrong. Nearly half were significantly different, and a third had the opposite direction to the reality (i.e. predicting a positive effect when it was actually negative).
Demographic surveys. Another analysis focused on the American Community Survey, which asks neutral demographic questions like whether a person is currently covered by any health insurance plan or whether the person has given birth recently. After removing obvious biases like question order, the AI’s answers were basically random. It only looked ‘good’ when the real responses were evenly distributed, because a random guess will also produce this pattern.
Psychometrics. One 2024 study found that LLMs tend to prefer socially-desirable responses in Big Five personality tests (e.g. higher on openness and lower on neuroticism), which suggests the model may echo human psychometric patterns but not necessarily how people actually behave. It’s a modern variant of what advertising pioneer David Ogilvy once warned about: ‘The trouble with market research is that people don’t think what they feel, they don’t say what they think and they don’t do what they say’.
Better AI or better data
Based on my quick playing around, it might be tempting to keep tweaking the prompt wording to get some better results. But as
has written about recently, simply chasing a better-worded prompt (i.e. prompt engineering) is not a robust or principled way to identify a stable, high-performing model.I suspect two main areas would improve results substantially, especially for political polling-type questions:
More detailed demographics. Ultimately a national vote intention (or career intuition) depends on the aggregated count of lots of different demographics and viewpoints. If we defined respondents in a simulation at a finer scale, e.g. with recent polling data and other persona features, I’d expect better results. Just turning up the temperature doesn’t add real diversity; it only makes the output wording more random. (I also learned that if you set temperature = 2, the results go off-piste very quickly.)
Model fine-tuning. Rather than using an out-of-the-box LLM, some fine-tuning using past survey data (perhaps with Thinking Machines new API) could allow for better handling of question-answer style and consistency with known trends in the data.
With the right tailoring, LLMs might be able to complement existing methods, particularly when questions cannot be easily defined in advance (i.e. to create a simple train-test dataset) and new data is hard to collect at scale.
Even so, there are likely to be several limitations with AI-based avatars as a substitute for traditional approaches:
Reliance on human data. Even if AI gets very good at predicting survey results, it will still need new up-to-date human data to stay on top of trends. For example, imagine we have an AI avatar that is 95% accurate. If we stop collecting real data, and instead use the avatars to generate insights, the next set of avatars will be 95% accurate at capturing simulations that are 95% accurate. So after 10 iterations, a rough back-of-the-envelope would suggest we’d have a model that’s only 0.9510 = 60% able to capture reality.
New situations are hard. When the UK COVID ‘lockdown’ came in on 23rd March 2020, YouGov reported that 93% of Britons supported it. Would anyone have predicted this even at the start of that month? And would they have believed it had the population not be surveyed?
Correlation matters. Understanding populations is about more than just predicting how individuals will respond to a particular question. We also need to capture correlations among individuals’ responses, and how those dependencies affect aggregate survey results. For example, in late October 2024,
correctly pointed out the US presidential race unlikely to be close; correlation in polling errors meant a definitive victory for one side or the other was more likely than someone edging it. The same principle applies when using AI avatars to simulate survey responses: if avatars’ opinions aren’t correlated in realistic ways, aggregate results will be misleading, no matter how many avatars we use.
One of the things I’ve learned over the years, whether researching health or behaviour, is that better data analysis methods can help a lot if you need better estimates. But if you really need a reliable answer about what’s happening right now, often the best thing is to go out and collect some data first.
Technically, you could extract the model’s internal log-probabilities for each option instead of running hundreds of generations. This would give a cleaner estimate of its uncertainty. But this was just a quick, nap-time experiment to get a reasonable sense of what the outputs look like.
Your nap-time experiment with synthetic surveys is such a fun way to test the promise and limits of LLMs. It's fascinatng to think about using models to predict survey outcomes, but as you noted there are still quirks in capturing nuanced human behaviour and local context. Digital twins can augment our understanding but they should complement, not replace, real-world data and ethics consderations. I'd love to see more experiments like this to calibrate where these tools add valie and where they fall short.