

Large language models (LLMs) like GPT-4 have an increasingly impressive ability to generate answers, images, and code. Yet they can also be underwhelming when it comes to tasks that require domain expertise.
For example, suppose we give ChatGPT (using GPT-4) the following instruction: ‘Write R code to calculate disease severity from cases and deaths’.
As any specialist in outbreak analysis will tell you, the challenge with such a calculation is that there is a lag between people becoming ill and dying/recovering. For example, suppose 100 people become ill today and all are still alive. This doesn’t mean the fatality risk is 0%; it just means we don’t know the outcomes of all these infections yet.
As a result, we can’t just divide total deaths to date by total cases to date when estimating severity. We need to adjust for delays. Unfortunately, GPT-4 does not account for this crucial bias by default, and instead returns us a function based on the following erroneous calculation:
cfr = (deaths / cases) * 100ChatGPT gives the below caveat, but leaves users none the wiser about this delay.
Remember, the CFR is just one measure of disease severity and should be interpreted with caution, as it can vary depending on how cases and deaths are reported and the stage of the disease outbreak.
So is there a better way to provide information and methods to people interested in these sorts of questions?
Adding domain specifics
The transformer algorithm that powers many large language models (i.e. the ‘T’ in GPT) consists of two parts: an encoder and decoder. The encoder takes the input text and converts it into a set of numerical values that capture key aspects of its meaning, while the decoder takes this vector and uses an underlying generative model to produce a text (or image, or code) response.
So if we put a query into ChatGPT, the encoding and decoding is happening under the hood, hidden from the user, who just receives the answer:

But what if we pull the algorithm apart, to help us input better domain knowledge into the LLM? Helpfully, we can do this directly with an ‘embedding model’ provided via the OpenAI API. For example, if we input the text ‘Write R code to calculate disease severity from cases and deaths’ into the model, we get a list of 1536 numbers. We can visualise this ‘embedding’ as follows:

Mathematically, this list of numbers represents a vector pointing in a specific semantic ‘direction’. So if we have another embedding (perhaps from another lump of text), we can work out whether these two embeddings are pointing similar directions or different ones1.
The advantage of this vector comparison approach is that it’s much faster to calculate, because all the relevant embeddings for comparison can be generated ahead of time, and the similarity metric can be calculated locally, without needing an LLM.

But what are some relevant documents (and hence embeddings) for outbreak analysis? In the past year or so, my colleagues and I have been working on the Epiverse initiative, creating and contributing to a range of open-source R packages to help with common tasks. Historically, researchers have developed a lot of useful statistical and epidemiological methods, but often there isn’t an easy-to-use tool available that is stable with good documentation (this is also a regret in my own past work).
Let’s start by embedding all the documentation of the newly created Epiverse packages. This involves splitting the big files up into smaller chunks of text and code, then embedding each of these chunks. This results in a few hundred vectors we can then compare with the above user query.
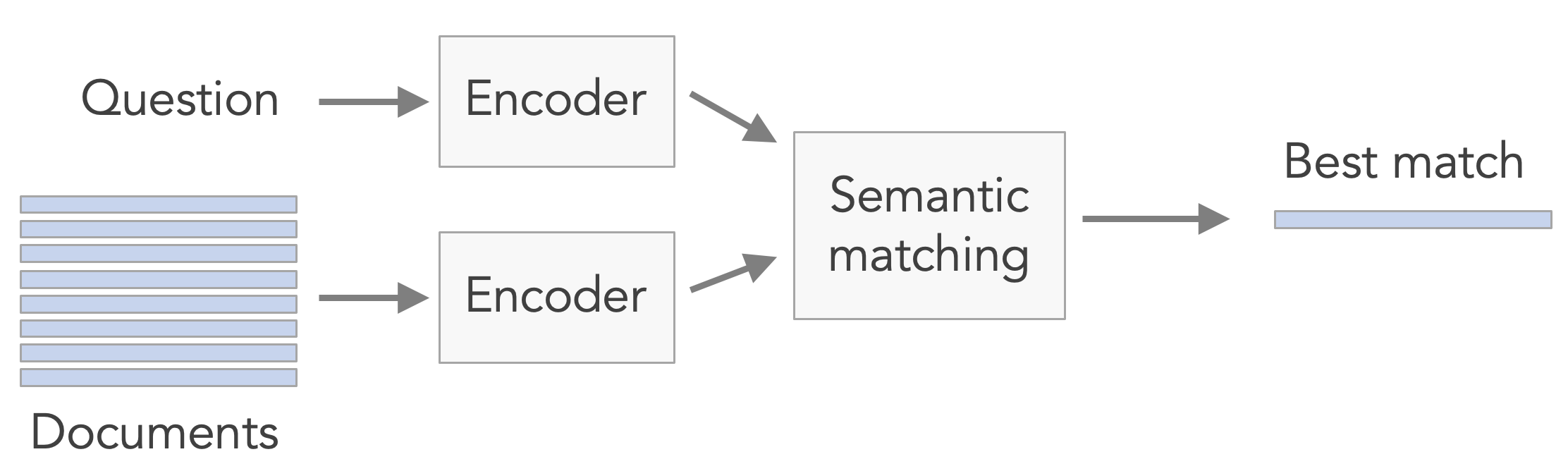
When we compare the vector from the user input to all the vectors produced from the Epiverse documentation, the closest match in terms of semantic ‘direction’ is a chunk of text from the basic severity calculation walkthrough in the cfr package. Which is a great place to start, given it describes a method that we’ve used in real-life for outbreaks ranging from Ebola to COVID. The second-best match comes from the cfr ‘get started’ page (again, a good place for a user to begin). And the third best is the documentation for the cfr_static function, which is the main method described in the two top matching documents.
Turning documents into code
We don’t have to stop here. Now we’ve got a method that can identify relevant sections of documents, we can pass the best matching documents as context to GPT-4, and get it to generate a more detailed answer for us. (Note: here we’re working with chunks of MIT licensed Epiverse content, but make sure you’ve thought about rights/restrictions before sending anything to a LLM server, and appropriate credit for any results displayed.)
Structurally, what we’re doing is similar to the functionality behind the new GPTs feature from ChatGPT, and the more customisable ‘assistant’ development feature in the OpenAI playground. However, these tools don’t always produce useful outputs out-of-the-box, so I’ve found there’s a lot of value in thinking deeper about how the process works, and how to finesse the process of searching for relevant context then passing it to the LLM. In the field, this is known as ‘Retrieval Augmented Generation (RAG)’, and lots of useful resources/templates have emerged in recent months if you’re interested in exploring more.
So, let’s take top 5 matching chunks of text from above and send them to GPT-4 along with the original user query (there’s a tradeoff here, as too much text will slow down the GPT request, whereas too few will produce an unreliable answer). We can also add an accompanying prompt telling GPT to only use the context provided and format the output as code.

If we do this, GPT generates the following R code output (if you’re not a fan of code, or R, feel free to skip to the plot below):
# Load the necessary library
library(cfr)
# Assume we have a data frame `df` with columns "date", "cases", and "deaths"
# df <- data.frame(date = ..., cases = ..., deaths = ...)
# Calculate the naive CFR (without correcting for reporting delays)
naive_cfr <- cfr_static(df)
# If you have information on reporting delays from past outbreaks, you can correct for these delays
# Assume the delay is Gamma distributed with shape k = 2.40 and scale theta = 3.33
corrected_cfr <- cfr_static(df, delay_density = function(x) dgamma(x, shape = 2.40, scale = 3.33))
# Print the naive and corrected CFR
print(naive_cfr)
print(corrected_cfr)Fortunately GPT didn’t hallucinate any make-up functions, and a quick glance suggests the code should run once we add some data.
But does it do what need?
Let’s test the suggested code using data from the 1976 Ebola outbreak, which had the following pattern of cases and deaths:

If we just take the data available up to the middle of the outbreak (e.g. 23rd September 1976), we’d expect the simple deaths-divided-by-cases calculation to have a substantial bias, because there’s a clear lag between the two. Indeed, this naïve calculation produces an estimate of 47% (with a 95% confidence interval of 39-56%).
If instead, we use the above code, it should adjust for the possibility that some cases may not yet have a known outcome in real-time. And that’s what it does. When we input an appropriate distribution for delay from onset-to-death for Ebola2, the code produces an estimate of 94% (73–100%).
In reality, once the 1976 Ebola outbreak had ended – and hence all outcomes of cases were known – there were a total of 234 deaths in the dataset among 245 cases, a fatality risk of 96%3.
What next?
This is just one brief example showing how combining LLMs with domain knowledge can turn a bad default calculation into something more useful. There’s much more to do in this area – from refining prompts to improving the matching process – and we’ll hopefully have more to show soon.
In the meantime, I think the above illustrates a few important points:
Default general LLMs struggle at many domain specific tasks, but there’s lots we can do to improve performance with tailored inputs via Retrieval Augmented Generation.
Outbreaks often involve a mix of specific contexts/situations and somewhat predictable questions and methods. So having the ability to rapidly tailor and scale tools could be really useful for future outbreak analysis.
There’s value in getting a slightly deeper understanding of how emerging tools like GPTs and RAG work, to guide our thinking about what might be possible and how these tools could be improved.
Like many fields, outbreak analysis is full of long-standing bottlenecks and domain-specific insights that can be hard to come by. Sal Khan’s talk at TED earlier this year helped convince me that there’s a better way to solve some of these problems.
It will be exciting to see what the community can do next.
A common method to do this is to use cosine similarity.
In this case, it happens to be the distribution given in the code output, because it’s included as an example in the cfr package documentation.
If we go to the best-matching walkthrough page, we’ll get more info about why the adjustment worked.
Very interesting. I didn't know it was possible to dial-in these tools in this way. It highlights that these really are tools needing user input/guidance and not some sort of unfathomable answer engine.