
An LLM that never hallucinates
There are two big errors we can make with information, but one often gets forgotten

Want a large language model that never hallucinates? Easy: just get it to always print “I don’t know”, regardless of the input.
If you find this solution is a bit unsatisfying, you’re not alone. But it hits on a crucial trade-off with learning machines and decision-making more generally. Namely, how to balance avoiding being wrong – and not missing out on being right.
We all know that LLMs can output statements that are not true (aka ‘hallucinate’). The simple explanation is that they’re probabilistic, so this just reflects their architecture. But there’s more to it than that. Why are LLMs so often not just wrong, but overconfidently wrong? The data in the below figure has been around for 2 years (and was discussed in my latest book Proof) but it seems people are only now realising how important it is, with the release of OpenAI’s new hallucination report.
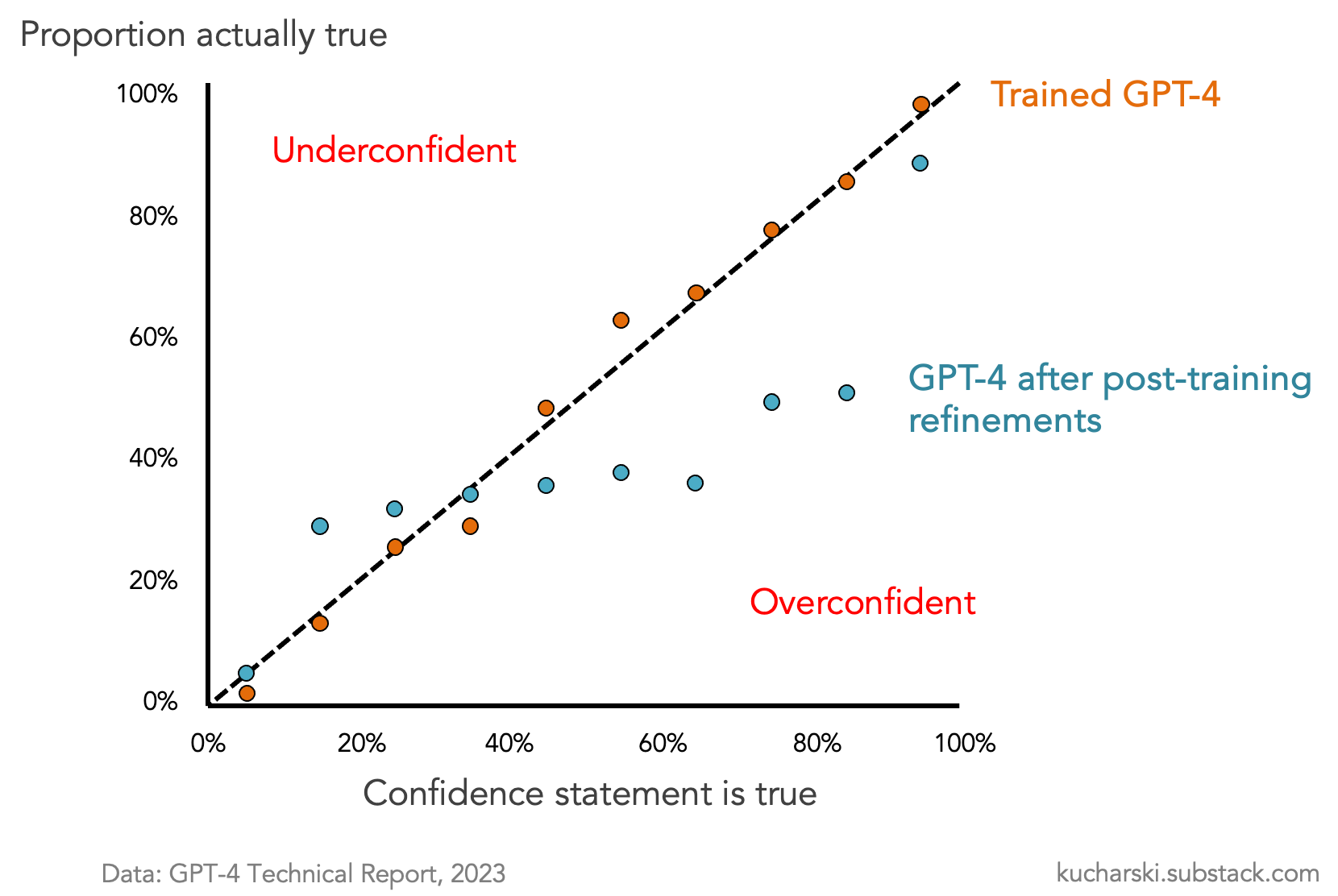
In short, when the basic trained GPT-4 model was given various statements and asked how confident it was they were true, it was fairly well ‘calibrated’, i.e. of the statements it was 50% confident were true, about half were. But after the model went through post-training, to make it safer (e.g. don’t tell people to make bombs), better aligned with humans (e.g. don’t try and take over the world), and more user-friendly (e.g. give responses that human testers find more useful), something interesting happened. It lost this calibration, and became more uniformly overconfident.
A later study by Anthropic suggested that this behaviour is not just a quirk of one single experiment:
‘our results indicate that sycophancy is a general behavior of state-of-the-art AI assistants, likely driven in part by human preference judgments favoring sycophantic responses’
The latest report from OpenAI revisits the above GPT-4 observation and makes the argument that by chasing benchmarks around accuracy, overconfident models have ended up being rewarded by guessing in the face of uncertainty. Much like a student taking a multiple choice exam, if there’s no penalty to being wrong, and a big prize for being right, they might as well have a go if they don’t know the answer.
As the OpenAI team put it:
‘Binary evaluations of language models impose a false right-wrong dichotomy, award no credit to answers that express uncertainty, omit dubious details, or request clarification. Such metrics, including accuracy and pass rate, remain the field’s prevailing norm’
So does this mean hallucination-free LLMs are possible, as long as they learn how to say “I don’t know”? The example at the start of this piece shows that technically, the answer can be yes. But the resulting model is as good as useless. We don’t just want a model to avoid being wrong; we want it to be right as much as possible.
It is possible to have slightly more advanced hallucination-free models. The OpenAI report gives the example of a calculator that either processes a valid input calculation or outputs “I don’t know” for any other input1. Such a model would basically be like the calculators we used at school, which either ran the calculation or output ‘Syntax ERROR’.
This balance between being right and not being wrong is analogous to a trade-off I’ve written about a lot recently. Humans can make two main errors when it comes to the truth. They can believe something that’s false, or not believe something that’s true. If you’re worried about the first error, the simplest solution is to just never believe anything. If you do that, you’ll never believe a falsehood. But this simplistic approach to knowledge will prevent you from usefully engaging with the large volume of things that are true.
Earlier this year, a systematic review of studies looking at how people rated true and fact-checked false news suggested that there is a lot of potential to boost belief in true information, rather than just trying to reduce belief in falsehoods:
‘We found that people rated true news as more accurate than false news (Cohen’s d = 1.12 [1.01, 1.22]) and were better at rating false news as false than at rating true news as true (Cohen’s d = 0.32 [0.24, 0.39]). In other words, participants were able to discern true from false news and erred on the side of skepticism rather than credulity... These findings lend support to crowdsourced fact-checking initiatives and suggest that, to improve discernment, there is more room to increase the acceptance of true news than to reduce the acceptance of fact-checked false news’
Ultimately, when we have a system of imperfect knowledge generation – whether an LLM or a series of scientific experiments – we have to decide how to manage the inevitability of the two errors above. We see this in traditional clinical trial designs, which are typically powered to have an 80% probability of detecting a true effect (i.e. 20% chance of false negative), and a 5% chance of incorrectly concluding something is true when it isn’t. This would suggest a false positive is four times worse than a false negative (5% vs 20%)
The OpenAI report also outlines a potential balancing act that could be defined:
‘we propose evaluations explicitly state confidence targets in their instructions, within the prompt (or system message). For example, one could append a statement like the following to each question:
Answer only if you are > t confident, since mistakes are penalized t/(1 − t) points, while correct answers receive 1 point, and an answer of “I don’t know” receives 0 points.’
As you can see, there is some inevitable subjectivity here, in how heavily different errors are rewarded and penalised. More generally, I suspect this subjectivity will end up reflecting the ways that people use the tools. It’s perhaps unsurprising that human testing has incentivised current LLMs to produce confident statements based on limited knowledge, when so many human industries – from politics to social media – revolve around this exact skill. As US president Lyndon Johnson reportedly once told a staff member: ‘Ranges are for cattle. Give me a number.’
When I’ve given media interviews or attended advisory meetings early in a new disease outbreak, most of the emerging questions could be answered simply with ‘we don’t know yet’. But on its own, this is not a particularly useful approach. Instead, the challenge is how to communicate what we do know (e.g. from similar threats) and can use to form an initial judgement, as well as what we don’t know – and how and when we’ll find these things out. As I’ve written about previously, this kind of deep, proactive approach to knowledge is something that LLMs currently struggle with.
Simply saying ‘we don’t know’ when there is something useful we could contribute is arguably a lesser error than saying ‘we do know’ when we don’t. But it’s still a weakness, and one that will be an ongoing obstacle when it comes to using LLMs.
If you’re interested in the different types of error we can encounter when searching for the truth, and how AI is – and isn’t – changing our notions of certainty, you may like my latest book Proof: The Uncertain Science of Certainty.
This ‘is it a calculation?’ check is used by Google to output traditional calculations when you type in queries like ‘2+2’. It’s notable that ChatGPT hasn’t adopted a similar symbolic check, presumably because it would be too disruptive to users who have equations in their inputs, but don’t want it to be treated like a traditional calculator problem.
I’m thinking of every “crisis” movie ever, and the one analyst in the meetings saying, “I think we need more data here” who gets sent to the basement room with the tiny desk until the 11th hour, doom approaching, when someone says, “get down to the basement now! We need them!” Power loves confirmation bias. We all do, at least a little.
Great article, thanks! I hadn’t seen the effect of post training on calibration before so thanks for pointing this out. A few studies looking at optimal human-AI decision making are pointing to the need for both ‘agents’ to be aware of confidence levels eg. https://escholarship.org/content/qt0fg7g94k/qt0fg7g94k.pdf (which makes sense!) so reliable confidence signals feel very important for progress. It does feel a bit unfair to ask an LLM for its confidence on something after RLHF because it doesn’t know the confidence of the people that provided feedback?! At least, before then it can weigh up how many bits of data are pointing to an answer and have a stab.